En un vídeo de publicado por Raúl aka Megabyte titulado atacando al atacante, se muestra al final una herramienta privada a la que denomino Armageddon, yo había oído de esta herramienta hace unos años. Pero no la conocía de primera mano mi la había visto operar.
Conclusiones.
Dicen que no se debe hablar mal de la memoria de los finados, pero me ha decepcionado mucho, todo parece indicar que la herramienta fue programada con Visual Basic 6 lenguaje obsoleto desde inicios del nuevo siglo, nadie debería usar Visual Basic 6 pasado el año 2000
Me queda claro que fuera de las habilidades de intrusión le faltaba mucho de programación y ya ni hablar de la estructuración de una base de datos, más que criticar a Raúl, el Armageddon que hizo me da la oportunidad de mostrar como optimizar una DB de casi 100 millones de registros en una forma usable con una respuesta casi inmediata y eso será mi foco central en el artículo es MySQL y MariaDB pueden con el trabajo.
Se puede ver en las imágenes que para hacer una consulta debe desplegar una lista y seleccionar un estado, incluso en la lista se ve que el DF esta fraccionado en DF1 , DF 2 y DF 3
En esta otra imagen se ve cómo tiene que seleccionar una opción de búsqueda si será solo por nombre, por nombre y apellido paterno o nombre completo, eso es totalmente impráctico en la lógica del programa por código debe estar implementado cual será el medio de búsqueda de acuerdo al estado de los textbox por ejemplo de apellido materno, no pareciera que fuera muy difícil condicionar a que si el textbox esta vacío internamente se interprete como que no podrá buscar por apellido materno
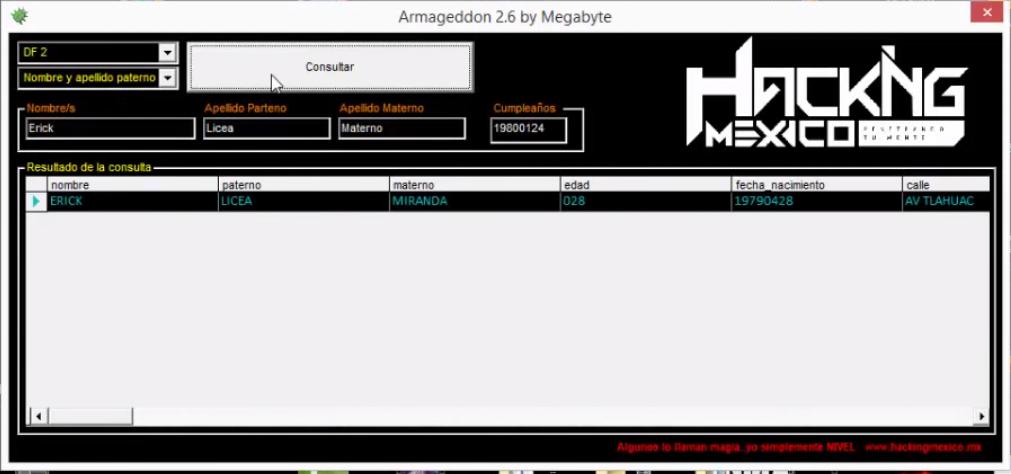
Es hasta el segundo intento que logra encontrar a la persona en la lista de DF 2, una pregunta más interesante seria, que pasaría si no conoce el estado en el que radica la persona que está buscando, tendría que ir recorriendo el scroll de su lista de estado uno por uno y así hasta lograr encontrar a la persona, suena como la cosa más impráctica del mundo, para ser una herramienta privada hecha por un hacker y usada por un hacker suena absurdo.
Finalmente puedo concluir que el archivo de la base de datos es un ridículo Microsoft ACCESS , yo preferiría usar SQLite o BDB antes que usar Access. Sin saber puedo deducir que de hecho era un archivo Access por cada estado
¿ Que haría Last Dragon ?
Lo que hice fue ir a la Deep WEB encontré una copia en archivo de texto de la DB que usa Armageddon el archivo pesa 23 GB y está separado por comas, el cual es muy impráctico porque algunos campos internos usan otro carácter para usar las comas por ejemplo MEXICO’DF en lugar de México, DF debido a que la coma se usó como separador de columnas
Ya con el archivo de texto creé una DB a la que llame INE asumiendo que el archivo es una copia del INE aunque no lo pude confirmar, aunque usar INE como nombre hace que el nombre se vea más dramático.
Procese el archivo con mysqlimport pasándole lo parámetros necesarios como delimitador de columna, de línea, etc, etc. Termine con una tabla gigantesca con motor InnoDB, muy buen motor para integridad relacional en MySQL pero pésima idea para una DB de solo consultas
La convertí a MyISAM debido a que con este motor no me da integridad relacional sino procesamiento rápido de índices en cada QUERY que es justamente lo que necesito para el laboratorio de este articulo.
Al terminar tenía una tabla gigantesca MyISAM de 90 millones de registros según en la Deep WEB es la información de más del 90% de la población en México, debe ser cierto porque me encontré a mí mismo afortunadamente con una dirección de una casa que renté y no contenía información de mi ultimas residencias que aunque tambien retandas y abandonadas no aparecían por lo tanto debe estar des actualizada un par de año.
Empecé a fragmentar la tabla gigantesca en tablas más pequeñas, aunque MyISAM no permite hacer relación de llaves foráneas eso no evita que uno lo intente de forma lógica y por cuenta propia, así que seccione en 10 tablas, una tabla para el perfil de búsqueda por nombre y apellidos, otra para el nombre de las calles, otra para las colonias, etc. Todas las tablas fueron relacionadas por una pseudo llave foránea , cuando por fin termine. Borre la tabla gigante original quedándome con N cantidad de tablas teniendo como raíz una tabla llamada perfil
Cualquiera pensaría que ya esta resuelto, pero no es así, hacer una consulta select con un where por nombre y apellidos seria tan malo como lo hace armageddon.
En una DB con tablas que contienen 90 millones de registros hacer un
Select nombre,apaterno,amaterno where nombre = ‘Daniel’ and apaterno = ‘Romero’;
Esa sentencia tarda aproximadamente unos 4 minutos en ejecutarse, lo cual es IMPRACTICO y ya ni hablar si en lugar de una condición directa se usa un LIKE; vete por un café que tomara como 6 minutos.
¿ Como se puede consultar tantos millones de registros, MySQL puede con el trabajo ?
Claro que puede y le sobra siempre y cuando sepas como estructurar tu DB.
Para afinar la DB yo usaría índices FullText.
CREATE FULLTEXT INDEX indicenombre ON ine (nombre);
CREATE FULLTEXT INDEX indiceapaterno ON ine (apaterno);
CREATE FULLTEXT INDEX indiceamaterno ON ine (amaterno);
Se puede agregar el índice con varios campos, pero para esta solución, me gusta la idea de un índice individual en un lugar de uno grupal, por el tamaño de la DB tomara aproximadamente 5 minutos por cada índice por el gran tamaño de la DB, así que 15 minutos después tendremos los 3 índices. Terminado de crear los indices ya se puede consultar usando los índices, para usarlos se puede usar 2 métodos, búsqueda tipo LIKE o búsqueda Booleana. Para este tipo de consulta yo usaría búsquedas Booleanas
En el modo Like
select * from perfil where Match (nombre) AGAINST ('Raul');
Esta sentencia traería a todos los Raules en México sin importar que tenga 2 nombres, como Raúl Antonio, o Raul XApellido y cualquier apellido materno y paterno
Para afinar la búsqueda usaría el índice con modo Booleano para encender o apagar palabras
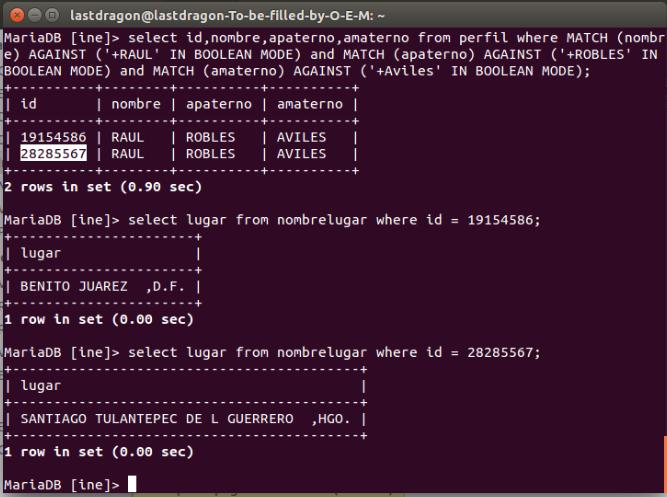
select * from perfil where Match (nombre) AGAINST ('+Raul' IN BOOLEAN MODE) and Match (apaterno) AGAINST ('+Robles' IN BOOLEAN MODE) and Match (amaterno) AGAINST ('+Aviles' IN BOOLEAN MODE);
Este último QUERY le dice a MySQL o MariaDB que usando índices solo traiga donde coincida el nombre obligatoriamente la palabra Raúl en apellido obligatoriamente debe tener la palabra Robles y en apellido materno obligatoriamente debe tener avilés, con el signo más la volvemos obligatoria, pero con el signo menos seria que obligatoriamente no debe contener la palabra para que se cumpla la condición, el resultado de esta búsqueda es que traería todos los Raúl Robles Avilés en la DB que por cierto en la DB que conseguí son 2, claro que usando índices la consulta no tardaría ni segundo, solo una fracción de segundo en lugar de los 5 minutos que podría tomar usando un where sencillo. Tambien se pueden buscar más palabras por columna como (‘+PrimerNombre +SegundoNombre’ IN BOOLEAN MODE) y debe cumplirse la condición de que las 2 palabras estén presentes en ese Varchar, Varchar es el tipo de campo que use para esta tabla es más lento que Char pero en una DB con millones de registros usar un Char de tamaño estático podría resultar en un desperdicio de gigabyte en disco duro.
Demostrando la eficiencia de las tablas relacionadas de un MySQL contra el Armageddon hecho en ACCESS y VB6, para eso buscare al mismo Erick Licea y en una fracción de segundo me traerá a todos los Erick Licea en México, incluida la llave primaria ID que me podría servir para una segunda QUERY y conseguir más datos, recordando que separe la tabla grande en tablas más pequeñas, pero pseudo relacionadas lógicamente. En la imagen hago 2 consultas separadas para que se pueda apreciar la diferencia en segundos y toda la consulta sin tener que seleccionar estados ni fraccionar al DF en 1, 2 o 3
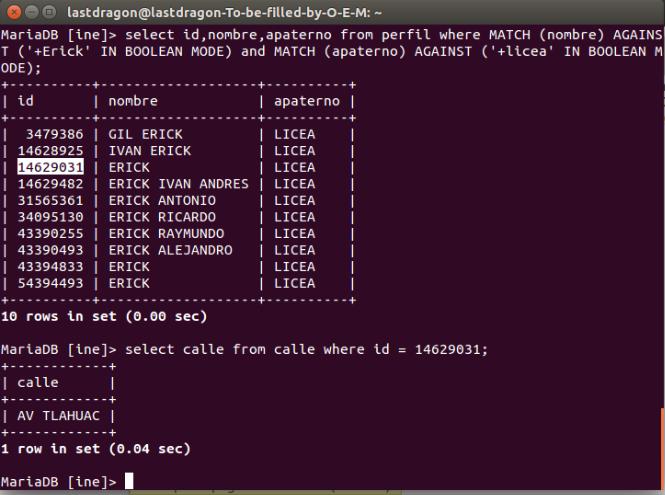
También podemos buscar por todos los Raúl Robles Avilés, encuentra 2 y podemos deducir que el del DF es Megabyte
Finalmente, si se quisiera hacer una herramienta privada usaría Java o C#, posiblemente mas Java para hacerlo multi plataforma en el DESKTOP el cual solo sería un cliente ligero conectando a la DB MySQL para poblar los campos en la aplicación o formularios en una página WEB con Python o PHP
Se que al final me llegaran peticiones sobre la DB que he sacado de la Deep WEB, para el momento de escribir esto ya la había borrado pues no encontré nada útil que hacer con ella, excepto tal vez presumir que se dónde vives, aunque esta información sigue estando al alcance de todo el que navegue por la Deep WEB e incluso en Tepito, nuestra privacidad fue violada y hecha pública desde que se publicó a la venta en DVD o CDs en Tepito, que buen trabajo hacen los administradores de los servidores del gobierno, ¿ que se puede esperar ? estamos hablando de las mismas personas que contrataron Hacker TEAM.
Con lo que he escrito aquí puedes hacerte de tu propia copia y optimizarla prácticamente es del dominio público, no es que sea ciencia de cohetes y eso nos devuelve al tema con el que inicie este POST, ¿ porque Raúl reconocido como un Hacker escribió un sistema tan malo para encontrar personas ?, tan falto de usabilidad, eso… Tal vez nunca lo sepamos.
La siguiente liga te lleva al momento del video donde se ve que usa Armageddon 2.6
Por lo menos daños indicios de dónde encontrarlo xD estaría bueno crear un servidor mysql en la nube para hacer consultas y más que con VB6 sería con php para poder mantener más secreto el asunto y que no Callera en malas manos
Yo tengo una de telcel, quien me ayuda a montarla en un systema asi ? Ojala me ayuden
¿ Cuantos millones de registros ?
Excelente articulo, aunque personalmente prefiero mas usar Mssql por la facilidad de optimizar las consultas (y que te diga el mismo motor del sql donde la estas cajeteando), pero no esta demas saber que existe un parecido en mysql.
No tengo nada en contra de MSSQL, me gusta su desempeño. Si tan solo fuera FreeSoftware, algún día. C# algo “libre”, algún día tal vez SQL Server sea igual que C# y .NET
Seria interesante el ejercicio de ver como esos 2 motores manejan bases de datos masivas como la del ejemplo y ver los resultados.
Ya estoy en eso….
Esa data base la vende la “Letrafire” en youtube he visto videos , igual en cebollachan la puedes encontrar , hay un foro donde venden una de 400 GBs babylon2lkylk7d2.onion
Me conoces y sabes que yo no digo “buen artículo” por ser complaciente. Este es un buen artículo, buen trabajo.
Cómo descargaste 23 GB desde la deep web? cuánto tiempo te tomó? no se cortó la descarga?
Yo soy usuario de GNU/Linux , asi que hago script, nada que algo de BASH , algo de WGET no puedan resolver, no se cuanto tiempo tomo descargarse no estuve pegado a la PC hay otras cosas que hacer, no se si hubieron fallos durante la descarga, de eso se encarga el script y el resume de WGET
tienes el link de algunos foros o de este tipo de informacion de la deep web? como dices yo veo puro bloffeo en la deep web drogas armas etc etc de hacking he visto poco
Last Dragon pasa link donde encontraste esa DB, te lo agradecería y muy buen POST
Pasa link